
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 스프링
- 문서화
- API
- multimodule
- 성장
- Kotlin
- springrestdocs
- 스타트업
- 멀티모듈
- batch
- 프론트엔드
- springboot
- spring
- 회고
- 스프링부트배치
- 서브모듈
- springbootbatch
- batchframework
- 스프링배치
- submodule
- batch framework
- react
- 백엔드
- 스프링부트
- Today
- Total
노트북을 열고.
[spring boot batch] 1. 간단한 대용량 배치처리, 스프링부트배치 본문
대략 10만 명의 회원을 거느리는 웹서비스를 운영한다고 가정했을 때 우린 매일마다 회원들의 상태변화를 감지하고 운용할 수 있어야 합니다.
가령
오늘까지 우리 서비스에 접속하지 않은지 1년 이상이 지난 회원의 상태는 휴면으로 전환시키고 휴면으로 전환된 회원은 다시 로그인했을 때 본인인증절차를 거치도록 하는 것이 서비스 보안에 좋겠죠.

또는
후불로 청구되는 유료서비스를 이용하고 과금액을 미납한지 한 달째 되는 회원에 대해서도 매일마다 집계하여 그에 맞는 추심을 한다거나 채권관리대상으로 지정하여 우리서비스의 수익구조를 안정적으로 보호해야 하는 경우도 있습니다.

만약 이러한 일들을 사람의 손을 반복적으로 거쳐야 한다면 매우 고단한 일이 될 것입니다. 무엇보다 우린 그럴 인력을 고용할 돈이 없습니다.
스프링 부트 배치에 관하여
스프링 부트가 제공하는 스프링부트 배치(SpringBootBatch)는 다음과 같은 강점을 가지고 있습니다.
자동화 : 매번 단순반복작업을 쉽고 빠르게 자동화시켜줍니다.
대용량 처리 : 그것이 대용량이라 할지라도 가장 최적화된 성능을 보장합니다.
견고성 : 예측하지 못한 상황이나 동작에 대한 예외처리도 정의할 수 있습니다.
재사용성 : 공통적인 작업을 단위별로 재사용할 수 있습니다.
이렇게 좋은 배치처리 프레임워크가 있으니 당장 사용해야겠죠?
하지만 이 스프링부트배치도 배치 처리 특성상 몇 가지 고려해야 될 사항이 있습니다.
단순하게!
복잡한구조와 로직을 피해야 합니다.
안전하게!
정의한 단위수만큼 데이터를 불러와서 처리합니다.
처리해야 하는 데이터에 대한 예외적인 상황이 일어나지 않도록 데이터의 무결성이 보장되어야 합니다.
가볍게!
배처처리시 시스템에 입력(Input)과 출력(Output)의 사용을 최소화해야 합니다. 네트워크 비용을 커질수록 그만큼 성능에도 영향을 끼치기 때문이죠.
최대한 적은 횟수로 데이터를 가져와서 -> 처리하고 -> 저장하는 것이 좋습니다.
스케쥴러가 아닙니다!
착오하지 말아야 할 것이 스프링부트배치는 스케줄러가 아닙니다. 별도로 스케줄링 프레임워크에 구현된 스프링 부트 배치를 적용하여 원하는 시간이나 이벤트 상황에 실행되게 하거나 이력관리를 할 수 있어야 합니다.
스프링 부트 배치의 기본구조
스프링 배치에 공통적으로 정의된 시나리오는 다음과 같습니다.
Read(가져와서) : 원하는 조건의 데이터 레코드를 DB에서 읽어옵니다.
Processing(처리하고) : 읽어온 데이터를 비즈니스로직을 따라 처리합니다.
Write(저장한다.) : 처리된 데이터를 DB에 업데이트(저장)합니다.
이해하기 매우 쉽죠. 그저 '가져와서', '처리하고,' '저장합니다.' 이 기본구조를 스프링 부트 배치에서 제공하는 인터페이스 관계도를 나타내면 다음과 같습니다.

전 단계는 잠시 무시하고 방금 전 언급한 부분(파란색으로 색칠한 부분)만 살펴보겠습니다.
가져와서, 처리하고, 저장한다는 각각 다음의 인터페이스에서 정의합니다.
ItemReader : 배치데이터를 읽어오는 인터페이스입니다. DB뿐 아니라 File, XML 등 다양한 타입에서 읽어올 수 있습니다.
ItemProcessor : 읽어온 데이터를 가공/처리합니다. 즉, 비즈니스 로직을 처리합니다.
ItemWriter : 처리한 데이터를 DB(또는 파일)에 저장합니다.
ItemProcessor VS ItemWriter
지금도 단순하지만 (어차피) 더 단순하게 생각해서
1. 가져와서(ItemReader)2. 처리한다.(ItemProcessor)
2. 처리하고 저장한다.(ItemWriter)
이렇게 생각해 볼 수 도 있겠죠. 굳이 ItemProcessor와 ItemWriter 단계를 별도로 분리하지 않고 그냥 ItemWriter에서 처리하고 바로 저장하는 구조가 더 간결해 보일 수도 있겠습니다...만 이렇게 분리하는 데에는 다 이유가 있습니다.
1. 각각의 역할을 단순명료하게 분리하기 위함입니다.
앞서 설명드린 바와 같이 스프링 배치 부트는 배치 처리의 특성상 그 구조가 단순해야 합니다.
이미 역할이 정해져 있는 인터페이스에 본연의 역할외 다른 역할까지 정의하여 사용하면 처리가 이루어지는 분기 단위가 모호해질 수밖에 없습니다.
꼭 스프링부트 배치 프레임워크라서가 아니라 대용량 데이터에 대한 배치 처리는 100건이면 100건 1000건이면 1000건 과 같이 일정한 처리 단위로 최대한 단순하게 읽고 처리하고 저장되게 하는 것이 좋습니다.
개발자의 입장에서도 비즈니스로직을 살펴볼 때에 어디가 데이터를 읽어오고, 어디에서 데이터를 처리하며, 어디가 데이터를 저장소(DB, File)저장하는 영역인지를 명확하게 구분 지어 설계하는 것이 견고한 서비스를 만들어가는데 좋은 밑바탕이 될 수 있겠죠.
2. 읽어오는 데이터와 저장하는 데이터의 타입을 분리하기 위함입니다.
ItemReader(데이터를 읽어올 때)에선 DB 뿐 아니라 File에서도 읽어올 수 있습니다.
마찬가지로 ItemWriter(데이터를 저장할 때)에서도 역시 DB뿐 아니라 File에 쓰이게 할 수도 있습니다.
스프링부트 배치 프레임워크에서 제공하는 2개의 인터페이스를 살펴보겠습니다.
인터페이스 : ItemReader (데이터를 읽어올 때)
package org.springframework.batch.item;
import org.springframework.lang.Nullable;
public interface ItemReader<T> {
T read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException;
}ItemReader는 배치데이터를 읽어오는 인터페이스입니다. Read메서드의 반환 타입을 볼까요?.
제네릭(Generic) 타입입니다. 네 맞습니다. 제네릭이기 때문에 우리가 직접 타입을 지정할 수가 있습니다. 즉 ItemReader를 통해 읽어오는 타입은 우리가 직접 지정할 수 있습니다.
인터페이스 : ItemWriter (데이터를 저장할 때)
package org.springframework.batch.item;
import java.util.List;
public interface ItemWriter<T> {
void write(List<? extends T> items) throws Exception;
}ItemWriter의 write 메소드의 매개변수를 살펴볼까요? 제네릭(Generic)입니다.
아까 ItemReader 인터페이스의 반환타입이던 바로 그 제네릭(Generic) 말입니다.
매개변수는 우리가 원하는 타입을 리스트(List) 형태로 받습니다.
그렇다면 데이터를 한번에 몇 건씩 처리해야 할까요?
단순하게 ItemReader에서 반환된 모든 데이터를 한꺼번에 받아서 처리하면 될까요? 만약 읽어온 데이터가 1만건, 아니 100만 건이 될 수도 있을 텐데요. 그렇게 많은 양의 데이터가 한꺼번에 메모리에 올려지면 실제 서비스에 어떤 영향을 주게 될까요?
네 스프링부트 배치는 한 번의 트랜잭션 안에 처리(commit)되는 수를 정의할 수 있습니다. 그 역할을 하는 것이 바로 chunk라는 단위이지요. 이것은 스프링부트프레임의 가장 핵심적인 키워드라 잠시 후 다시 설명드리도록 하겠습니다.
마지막으로 ItemReader와 ItemWriter 중간에 있는 ItemProcessor를 살펴볼까요?
ItemProcessor (데이터를 처리할 때)
package org.springframework.batch.item;
import org.springframework.lang.Nullable;
public interface ItemProcessor<I, O> {
O process(I item) throws Exception;
}이 녀석(인터페이스)의 존재의 이유는 방금전에 소개드렸다시피 각각의 역할을 분리하기 위해 그리고 읽어올 때와 저장할 때의 데이터 타입이 다른 경우, DB에서 레코드를 읽어와서 파일 형태로 저장할 때 혹은 그 반대일 때를 대응하기 위함입니다.
이 인터페이스의 제네릭의 매개변수가 2개인데요. 앞에 있는 <I>는 Input을 의미하고 뒤에 있는 <O>는 Output을 의미합니다. 말그대로 인풋과 아웃풋 타입을 정의하여 process 메서드 안에서 우리가 필요한 비즈니스 로직을 구현합니다.
지금까지 설명한 내용을 하나의 그림으로 표현 하면 다음과 같습니다.

이 배치 프로세스가 돌아가는 가상의 시나리오를 설계한다고 가정해봅시다.
1. 데이터베이스에서 우리 서비스요금이 청구된 지 30일이 지난 고객 리스트를 읽어온다. (ItemReader)
2. 1번에서 가져온 고객리스트들을 대상으로 다음의 비즈니스를 처리한다. (ItemProcessor)
- 각 고객정보의 카드정보를 활용하여 자동결제를 시도한다.
- 자동결제를 시도하여 미납금액 결제을 정상적으로 처리된 고객은 요금 청구 완료상태로 전환한다.
- 자동결제를 시도하여 미납금액 결제를 실패로 처리된 고객은 서비스구독 이용정지상태로 전환한다.
- 자동결제가 성공한 고객에게는 결제가 완료됐다는 안내메시지를 등록된 휴대폰 정보를 통해 SMS로 발송한다.
- 자동결제가 실패한 고객에게는 서비스이용정지 안내 메시지를 등록된 휴대폰 정보를 통해 SMS로 발송한다.
3. 2번에서 처리된 고객리스트들를 저장한다. (ItemWriter)
실제 운영되는 서비스와 비슷한 상황의 가상 시나리오를 각각의 인터페이스의 역할에 맞게 분리하여 설계해보았습니다. 스프링 부트 배치 프레임워크가 없이 구현을 해야 한다면 이러한 일련의 과정을 거쳐야 하는 프로세스를 설계하는 모두 개발자의 몫이 되겠죠? 비즈니스 로직은 둘째 치더라도 대용량을 다루는 배치처리에 대한 안정성 여부는 또 다른 차원의 문제입니다.
이정도라면 스프링 부트 배치 프레임워크가 제공하는 기본구조가 개발자들을 위해 얼마나 단순하고 명확하게 분리되어 제공하고 있는지를 알 수 있습니다. 스프링 부트 배치 프레임워크가 제공하는 기본구조를 알았다면 이젠 그 기본구조(읽고, 처리하고, 저장한다)를 포함하고 있는 객체를 살펴보겠습니다. 바로 저 파란색으로 칠해진 부분이죠.

Step
기본구조(읽고, 처리하고, 저장한다.)는 Step이라는 객체에서 정의됩니다. 1개의 Step은 읽고, 처리하고 저장하는 구조를 가지고 있는 가장 실질적인 배치처리를 담당하는 도메인 객체입니다. 그리고 이 Step은 한 개 혹은 여러 개가 이루어 Job을 표현합니다. 그리고 1개의 Step은 위에서 설명한 것과 같이 ItemReader(읽고), ItemProcessor(처리하고), ItemWriter(저장하고)를 정의합니다.
Job
한개 혹은 여러 개의 Step을 이루어 하나의 단위로 만들어 표현한 객체입니다. 스프링 부트 배치 처리에 가장 윗 계층에 있는 객체이죠. Job 객체는 JobBuilderFactory 클래스에서 Job을 생성할 수 있습니다. 더 정확하게 표현하자면 JobBuilderFactory에서 생성된 JobBuilder를 통해 Job을 생성할 수 있습니다.
1) JobBuilderFactory
JobBulderFactory 클래스를 살펴보면 다음과 같습니다.
package org.springframework.batch.core.configuration.annotation;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.repository.JobRepository;
public class JobBuilderFactory {
private JobRepository jobRepository;
public JobBuilderFactory(JobRepository jobRepository) { // 1
this.jobRepository = jobRepository;
}
public JobBuilder get(String name) { // 2
JobBuilder builder = new JobBuilder(name).repository(jobRepository);
return builder;
}
}1. JobBuilderFactory의 생성자를 살펴봅시다. JobBuilder를 생성하는 JobBuilderFactory가 생성되는 시점에 JobRepository를 주입하여 JobBuilder에서 사용할 Repository로 설정합니다. 이 말인 즉슨, JobBuilder가 생성되는 전에 JobBuilderFactory는 JobRepository를 주입받게 되고 결국 JobBuilder는 해당 JobRepository를 그대로 사용하게 되니 결국에는 모든 JobBuilder는 모두 동일한 JobRepository를 사용하게 되겠죠.
2. get 메소드가 JobBuilder 인스턴스를 생성 후 반환하고 있네요. 그러니까 JobBuilderFactory에서 get메소드를 호출하게 되면 새로운 JobBuilder가 생성된다는 사실을 알 수 있습니다.
2) JobBuilder
JobBuilderFactory를 통해 JobBulder를 반환받았습니다. 이제 JobBuilder를 통해 Job을 생성할 수 있습니다. JobBuilder의 내부를 살펴보도록 하겠습니다.
package org.springframework.batch.core.job.builder;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.job.flow.Flow;
public class JobBuilder extends JobBuilderHelper<JobBuilder> {
public JobBuilder(String name) {
super(name);
}
public SimpleJobBuilder start(Step step) {
return new SimpleJobBuilder(this).start(step);
}
public JobFlowBuilder start(Flow flow) {
return new FlowJobBuilder(this).start(flow);
}
public JobFlowBuilder flow(Step step) {
return new FlowJobBuilder(this).start(step);
}
}각각 다르게 정의된 2개의 start메서드 그리고 1개의 flow메서드가 있네요.
반환 타입이 모두 Builder인 것으로 보아 사용하려는 의도에 따라 각각 다른 빌더 메서드가 분류되어 있는 것처럼 보입니다.
1. JonBuilderFactory에서 JobBuilder를 만들고
2. JobBuilder에서 Job을 생성하기 위한 Step(or Flow) 파라미터를 받아 그 목적에 맞는 JobBulder를 생성합니다.
3. Job은 Step(or Flow) 인스턴스의 컨테이너가 되기 때문에 생성하기 직전에 인스턴스를 전달받습니다.
이 원리를 잘 이해하시면서 위 원리대로 기본적인 Job 생성코드를 만들어 보겠습니다.
@Bean
public Job myJob(JobBuilderFactory jobBuilderFactory) {
return jobBuilderFactory.get("myJob")
.start(mystep)
.build();
}
@Bean
public Step mystep(
StepBuilderFactory stepBuilderFactory
) {
return stepBuilderFactory.get("mystep")
.<MemberIn, MemberOut> chunk(100)
.reader(myrReader())
.processor(myProcessor())
.writer(myWriter())
.build();
}
@Bean
@StepScope
public ListItemReader<Member> myrReader() {
List<Member> oldMember = memberRepository.findByStatusNot(MemberStatus.INACTIVE);
return new ListItemReader<>(oldMember);
}
public ItemProcessor<Member, Member> myProcessor() {
return Member::setInactive;
}
public ItemWriter<Member> myWriter() {
return ((List<? extends Member> memberList) ->
memberRepository.saveAll(memberList));
}
myJob
JobBuilderFactory를 주입받은 인스턴스를 통해 JobBulderFactory를 메서드체인 형식으로 빌드합니다.
.get("myjob") : job이라는 이름의 Job을 생성하는 JobBulder 인스턴스를 반환받고자 합니다.
.start(myStep) : myStep이라는 메서드에서 Step이라는 인스턴스를 생성하여 반환받습니다.
.build(); : 이 메소드를 통해 비로소 myJob이라는 Job이 빌드가 되면서 Job이 생성됩니다.
myStep
StepBuilderFactory를 주입받은 인스턴스를 통해 JobBulderFactory를 메서드체인 형식으로 빌드합니다.
.get("myStep") : myStep이라는 이름의 Step을 생성하는 StepBuilder 인스턴스를 반환받고자 합니다.
.<Member, Member> Chuck(100) : MemberIn 타입을 100건 단위로 읽어와서 MemberOut로 반환한다는 의미입니다.
.reader(myReader) : myReader를 통해 DB에서 원하는 조건의 데이터 레코드를 읽어옵니다.
.processor(myProcessor) : myProcessor를 통해 비즈니스로직을 작성하여 데이터를 처리합니다.
.write(myWrite) : 처리된 데이터를 DB에 저장합니다.
JobLauncher
Job을 구현하였다면 이제 구현된 Job을 실행시킬 수 있어야겠죠. 이렇게 구현한 Job은 JobLauncher 인터페이스에서 실행할 수 있게 해줍니다. JobLauncher 는 다음과 같이 오직 실행을 위한 Run이라는 이름의 메소드 한개만 가지고 있습니다.
package org.springframework.batch.core.launch;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.JobParametersInvalidException;
import org.springframework.batch.core.repository.JobExecutionAlreadyRunningException;
import org.springframework.batch.core.repository.JobInstanceAlreadyCompleteException;
import org.springframework.batch.core.repository.JobRestartException;
public interface JobLauncher {
public JobExecution run(Job job, JobParameters jobParameters) throws JobExecutionAlreadyRunningException,
JobRestartException, JobInstanceAlreadyCompleteException, JobParametersInvalidException;
}
마지막으로 하단에 있는 JobRepository 를 살펴봅시다.
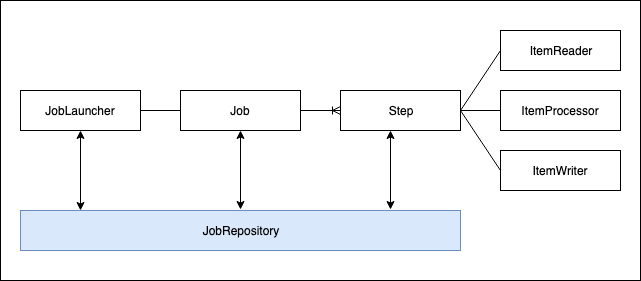
JobRepository
배치처리는 일정한 주기 간격으로 특정 조건을 가진 데이터를 읽어와서 처리하고 저장하는 구조를 가지고 있습니다. 이런 작업이 매번 반복되다 보면 가령 일주일 전부터 동작하는 Job이 그동안 몇 번 실행되고 언제 끝났는지를 알아야 하는 경우가 생기겠죠. 이러한 처리 정보를 메타데이터 형식으로 저장하여 관리하는 곳이 바로 JobRepository입니다. Job이 실행될 때마다 JobRepository에서는 배치 실행에 관련된 정보를 담는 도메인인 JobExcution을 생성합니다.
JobInstance VS JobExcution
두 단어가 비슷해 보이지만 의미는 완전히 다릅니다. Job이 한번 실행 될 때 JobInstance라는 실행 단위 인스턴스가 만들어집니다. JobExcution은 JobInstance에 대한 실행을 나타냅니다. 뭔가 설명이 막걸리스럽죠?
오늘 실행한 Job이 있다고 합시다. 위에서 설명한대로 JobInstance가 만들어지겠죠. 그런데 오늘 실행이 되어야 할 JobInstance가 예기치 못한 오류로 정상적으로 처리되지 않고 실패로 끝났습니다. 다음날 같은 시점에 Job이 실행될 때 어제 처리가 실패되었던 JobInstance는 그대로 끝나고 새로운 실행 단위인 JobInstance가 만들어질까요?
아닙니다. 한번 실패한 JobInstance는 그 다음날에 그대로 실행합니다.
그렇다면 그 JobInstance는 결과적으로 2번의 실행을 하게 되는 셈이죠. 그런데 만약 2번째 실행에도 실패했다? 그렇다면 그다음 날인 3번째 실행을 하게 되죠.(상남자답게 끝날 때까지 끝난 게 아니기 때문이죠.) 이렇게 1개의 JobInstance는 여러 번의 실행을 가질 수 있습니다. 그리고 그 여러 번의 실행 단위를 JobExcution이라 하죠.
자 뭔가 구구절절하게 전달해 드린 것 같아 일단 스프링부트 배치 프레임워크에 대한 기본적인 설명은 이 정도로만 하고 이 내용을 토대로 직접 기본적인 스프링 부트 배치 프레임워크를 활용하여 실제 동작하는 배치 Job을 다음 장에서 만들어 보겠습니다.
내용이 별로일 수 있습니다. 그러나 이것 하나만 기억해 두세요. 스프링부트 배치 프레임워크의 기본 구현원리는 단순하게 읽고(reader), 처리(processor)하고, 저장(writer)하는 구조라는 사실을 말이죠.
읽어주셔서 감사합니다.
이 지식에 도움받은 출처 공유드립니다.
1. jojoldu님의 기술블로그 - 기억보단 기록을.
Java중심의 Back-end 관련한 유용한 정보가 기록되어 있습니다.
jojoldu.tistory.com
2. (김영재 저) 처음 배우는 스프링 부트 2
입문서중에선 드물게 Springboot Batch에 관하여 자세하고 친절하게 설명해주고 있습니다.
www.yes24.com
'아는 것'보다 '알아야 할 것'이 더 많은 주니어 개발자입니다.
알고 있는 지식을 전한다는 목적 보단 막 알게 된 지식을 스스로 정리하는 차원에서 포스팅하고 있으니 잘못된 내용이나 부족한 부분이 있더라도 겸허한 이해 부탁드립니다. 댓글이나 쪽지를 통해 첨삭의견주시면 감사히 수렴하고 보완하겠습니다.
'SpringBoot' 카테고리의 다른 글
| [spring boot batch] 3. 배치실행의 모든기록. 메타테이블 (797) | 2019.09.02 |
|---|---|
| [spring boot batch] 2. 미납회원 배치처리 구현 (876) | 2019.07.30 |
| [SubModule] 4. 프로퍼티 설정하기 (432) | 2019.07.30 |
| [SubModule] 3. 멀티 모듈생성 (425) | 2019.07.30 |
| [SubModule] 2. 프로젝트 생성 (445) | 2019.07.30 |



